유튜브 댓글을 통해 사용자의 마음 이해하기
기술을 이용해 사용자 이해하기
UI, UX 디자인이라고 하면 결과물을 떠올리기 쉬운데요. 디자인을 도출하기 전에 사용자를 이해하는 것이 보다 중요합니다. 사용자를 이해하는 데는 관찰과 인뎁스 인터뷰 같은 정성 조사가 중심이 됩니다. 하지만 시간과 비용의 제약으로 한정된 사용자를 대상으로 하는 한계가 있습니다. 이를 보완하려고 사용자의 로그 데이터를 이용해 사용 패턴을 확인하는 정량적 조사를 병행하기도 했는데요. 요즘 pxd UXtech 랩에서는 자연어 처리 기술을 이용해 주관식 설문, 사용자 리뷰, 댓글 등 다수 사용자의 텍스트 데이터로부터사용자를 이해하는 도구를 만들고 있습니다. 자연어 처리 자체 연구보다는 저희가 잘할 수 있는 사용자가 어떻게 활용하고 UI에 적용할지를 고민하고 있습니다. :) 주기적으로 이런 기술을 활용해 다수 사용자의 생각을 읽어내고 거기에서 인사이트를 도출하는데 도움을 주는 도구들을 실험하고 활용하는 사례를 소개하려고 합니다.
유튜브 댓글에서 시청자의 마음을 읽기
대통령 선거에 많은 국민의 관심이 몰렸습니다. 여러 매체가 여론 조사나 인터넷 커뮤니티의 반응을 통해 국민의 선택이 어떻게 될지 점쳐 보려고 했습니다. 경제 전문 유튜브에 대통령 후보들이 초대되어 관심이 높았는데 댓글에 나라를 구했다는 말이 많아 반응 자체가 화제가 되기도 했고요. IT 제품이나 영화 리뷰 영상 같은 경우는 댓글에서 시청자가 공유한 유용한 정보와 노하우를 얻기도 합니다. 댓글을 모아보면 시청자의 반응 뿐 아니라 정보를 뽑아 낼 수도 있는데요. 눈에 띄는 댓글 들을 몇 개씩 읽어보기는 하지만 몇 천개, 몇 만개 되는 댓글을 사람이 하나 하나 읽고 정리하기는 어렵습니다. 유투브 댓글에서 시청자의 마음을 알 수 있는지 여러 실험을 해봤습니다.
어떤 이야기를 하나? 워드 버블로 보여주기
요즘 텍스트 분석을 활용한 뉴스나 기사들이 많이 나오고 있습니다. 가장 많이 보이는 것은 사용 빈도가 높고 관계의 중요도가 높은 주요 키워드를 뽑아 워드 클라우드로 보여주는 것인데요. 어떤 주제의 키워드가 많이 사용됐다는 걸 아는 건 흥미롭지만 어떤 맥락에서 사용됐는지는 알 수 없어 아쉽습니다. 대안으로 네트워크 그래프 형태로 키워드 간 관계를 보여주는 시각화도 많이 쓰이는데요. 정보량이 많다 보니 일반인이 해석하기에서는 복잡하고 어려워 보이기도 합니다. 기존 방법을 개선할 수 있는 방법을 고민해봤습니다.
어떤 주제의 얘기를 주로 하는지 알아보는 가장 기본적인 방법은 댓글에서 뽑아낸 단어들의 빈도를 계산해 주요 단어 순으로 나열하는 방법입니다. 사실 궁금한 건 단어가 아니라 어떤 주제를 많이 얘기했나인데 비슷한 주제를 다른 단어로 다양하게 표현하면 표(빈도)가 분산되어 잘 드러나지 않을 수 있습니다. 비슷한 의미의 단어를 단어군으로 묶고 빈도를 세면 분산되어 드러나지 않았던 주제도 찾아낼 수 있습니다. 단어군을 만드는 건 카카오브레인의 pororo 라이브러리를 이용해 워드 임베딩을 하고 유사도가 높은 단어를 클러스터링 하여 뽑아냈습니다. 엄밀하게는 문장에서 다른 단어들과 사용되는 관계가 비슷한 단어지만 대개는 의미가 유사한 단어들이 묶이는 경우가 많습니다. 이렇게 찾은 주요 단어군을 보로노이 트리맵으로 그려보았습니다. 보로노이 트리맵은 파이차트처럼 전체에서 개별 비율을 보여주는 차트인데 비눗방울처럼 둥글둥글 비슷한 모양의 덩어리로 보여 크기를 비교하거나 레이블을 붙이는데 파이 차트보다 장점이 있습니다.
조승연의 탐구생활 - 지구 멸망영화 비교하기 [90년대 vs 2022년] | 돈룩업 Don't Look UP, 아마겟돈 영상에 달린 댓글을 가져왔습니다.

어떤 맥락에서 키워드를 사용했나?
그럼 이 키워드들이 어떤 맥락에서 사용된 건지 궁금합니다. 하나의 키워드라도 여러 맥락에서 사용되고 있는데요. 키워드가 포함된 댓글을 모아서 의미별로 나눴습니다. 여기에서도 별도의 학습 없이 문장 임베딩을 이용해 댓글들을 비슷한 의미끼리 묶었습니다. 클러스터링 된 댓글들을 읽어보면 어떤 맥락들에서 사용됐는지 알 수 있습니다. 하지만 댓글을 다 보여주고 사람이 하나하나 읽어보도록 하는 건 너무 귀찮으니 맥락을 좀 더 쉽게 보여주는 방법을 찾아봤습니다. 문서를 요약하는 데는 대표 문장을 뽑거나, 문장들을 요약하거나, 대표 키워드를 뽑아 보여 주는 방법이 있습니다. 전자의 경우는 포털 뉴스에서 비슷한 기사들을 묶고 대표 기사를 상위에 표시하는 방식과 비슷합니다. 문장 요약은 기계 학습으로 요약된 문장을 생성해주는 언어 모델들이 있는데요. 짧은 블릿 형태로 요약이 되는 걸 바랬는데 현재 공개된 모델은 아직 기대만큼 품질이 좋지는 않았습니다. 아직은 다양한 도메인에 대해서 학습할 만한 요약 문장 데이터가 충분하지 않았던 것 같습니다.
차선책으로 주요 키워드 주변에 해당 키워드 클러스터의 맥락 키워드를 뽑아 나열했습니다. 트리맵으로 보여져 맥락이 사용되는 비율도 가늠할 수 있게했습니다. 키워드를 클릭하면 실제 댓글들이 구체적으로 어떤 맥락에서 사용되는지 토픽 덩어리로 묶어 확인할 수 있게 했습니다.
키워드를 뽑는 방법에는 문장 안에서 사용된 단어 중 뽑는 추출 요약과 의미를 포괄하는 단어를 제시하는 추상 요약 방법이 있는데요. 후자는 사과, 딸기, 오렌지, 바나나가 있으면 "과일"이라는 문서에는 없는 단어라도 대표하는 단어를 뽑아주는 방법으로 생성 요약이라도 합니다. 후자가 물론 좋긴 한데 별도 학습이 필요해서 통계적인 추출 방법을 사용했습니다. 키워드를 뽑는 데는 그래프 기반의 TextRank가 주로 사용되는데 저희는 TF-IDF와 임베딩 유사도를 함께 사용해 뽑았습니다. TF-IDF를 사용하면 단순히 많이 사용된 키워드가(Term Frequncy) 아니라 다른 토픽에서는 잘 사용되지 않는 특별한 단어(Inverse Document Frequency)를 뽑게 되는데요. 특이하기만 하고 토픽을 대표하지 못하는 키워드가 뽑히는 문제가 생길 수 있는데, 토픽으로 묶은 댓글 문장들과 키워드의 유사도를 계산해 별 관련이 없는 단어는 걸러냈습니다.

롱테일의 다양한 의견을 토픽 별로 보여주기
주요 키워드 중심이 아니라 처음부터 댓글들을 주제별로 묶어서 보여줄 수도 있을 텐데요. 사람이 분류하는 것처럼 깔끔하게 토픽 별로 분류하기는 어렵지만 임베딩된 의미 유사도에 따라 묶어주고 그 그룹에서 키워드를 추출하면 어떤 토픽에 대해 주로 얘기하고 있는지 한눈에 파악하는지 도움이 되었습니다. 토픽은 계층적 클러스터링으로 아주 비슷한 것을 먼저 묶고 점점 크고 포괄적인 그룹으로 덩어리를 만들 수 있습니다. 너무 많은 토픽을 한꺼번에 보여주면 복잡해 보이니 사람이 인지하기 10개 내외의 덩어리로(청킹- 매직넘버7) 보여주는 게 좋은데요. 설문 결과 등을 분석해 보여줄 때는 그럴듯해 괜찮았는데 유튜브 댓글은 도대체 무슨 얘기인지 알수가 없었습니다. 왜 그런지 살펴보니 설문은 닫힌 질문으로 답변의 범위가 한정되어 몇가지 유형으로 한정되어 예쁘게 묶일 수 있는데요. 댓글은 자유롭게 다양한 의견과 토론, 싸움이 뒤섞여 있는 다양한 주제의 롱테일 형태라서 적은 수의 그룹으로 묶으려 하면 이도저도 아닌 모호한 주제가 되어버리더라구요. 그냥 토픽별로 나누어 댓글이 많이 달린 순서대로 롱테일의 차트로 나타내고 관심 범위를 탐색하며 훑어보는 방법이 오히려 전체를 조망하는데 효과적이었습니다.
영화는 기후 위기에 대한 블랙코미디인데 댓글의 가장 주요 토픽 키워드로 코로나가 뽑힌게 재밌습니다. (미국)정부의 위기 대처가 영화랑 똑같다고 비판하는 내용들이고 그 중 트럼프 전 대통령의 코로나 위기 대응에 대한 댓글이 우선해서 뽑힌것 같네요.


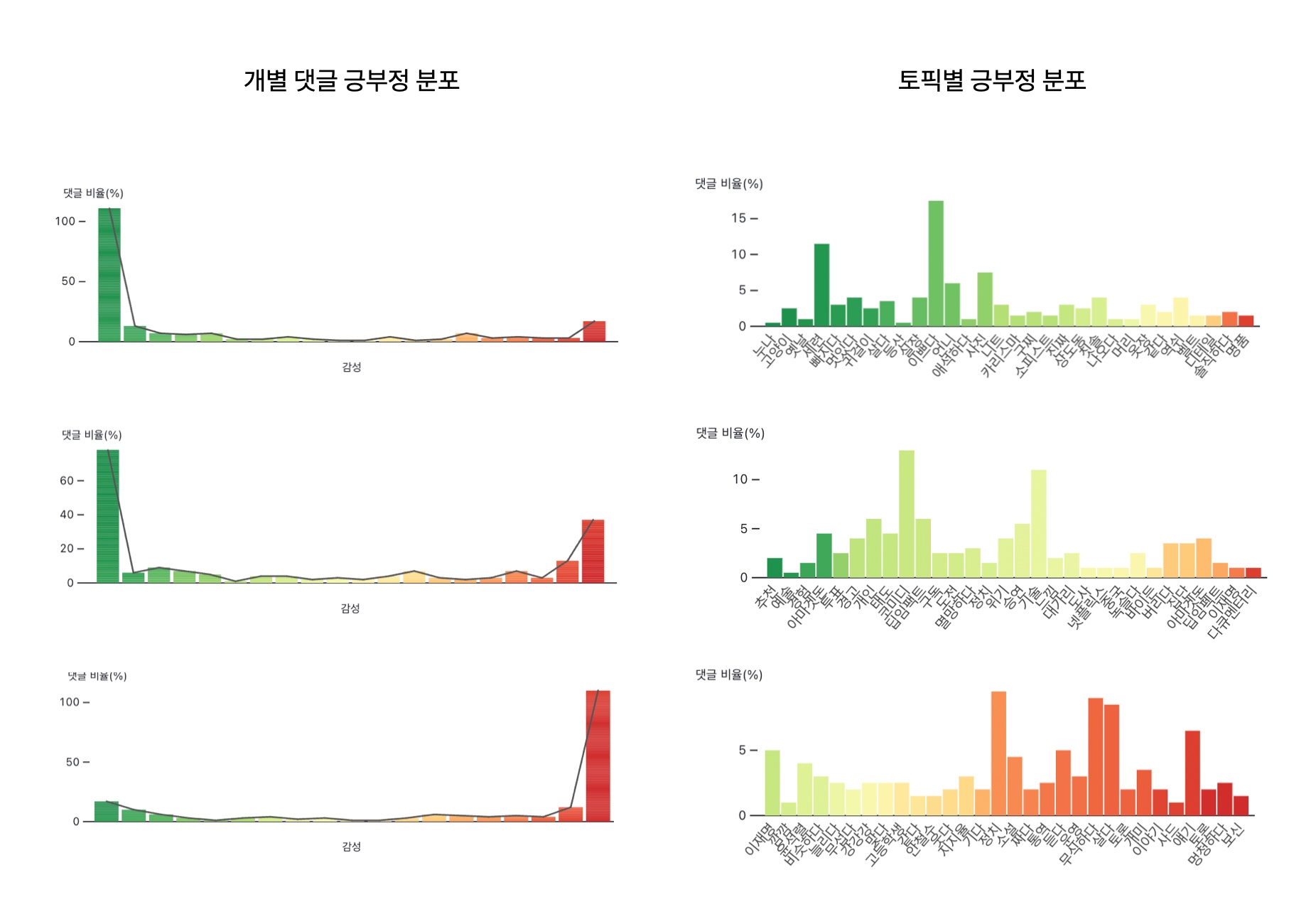
긍부정 분석
유투브 채널을 운영하시는 분들을 인터뷰하면서 칭찬하고 공감해주는 댓글에 힘을 얻고 욕설이나 부정적인 댓글에 상처를 많이 받으신다는 얘기를 들었는데요. 그래서 댓글을 긍부정으로 분류해 보여주는 것도 좋을 것 같습니다. Pororo 라이브러리의 긍부정감성 분석 모델로 분류를 테스트해봤는데요. 영화와 상품 리뷰 데이터를 학습한 모델이라 일반적인 문장에 적용하기는 한계가 있지만 댓글을 분류하는데도 어느 정도 효과가 있었습니다. 하지만 좋아요라고 칭찬하는 긍정적인 댓글들은 제법 잘 분류가 되었지만 부정에 가까운 분류는 꼭 부정적인 내용이 아닌데도 포함되는 경우가 있어(거짓 양성) 점수를 그대로 신뢰하기는 어렵습니다. 이런 부정적인 글을 분류하는 데는 혐오 발언 분류 모델로 찾아내는 것이 더 효과적일 것도 같습니다.
완벽하진 않지만 이런 댓글의 긍부정 점수 분포 자체가 영상의 성격을 보여 줍니다. 개별 댓글의 긍부정 분포를 보여주거나 토픽 별 긍부정 점수 분포를 보여줄 수 있는데요. 개별 댓글 긍부정 분포는 극단적인 분포가 주로 나타나 변별이 어려운데 토픽 별로 긍부정을 함께 표시하면 영상에 대한 전체적인 댓글의 성격을 쉽게 가늠할 수 있습니다.
우호적인 팬덤을 가지는 채널의 영상은 전체적으로 대부분 토픽이 긍정적인 초록으로 나타나고, 정보 전달 채널은 중립적인 토픽의 댓글이 많고 정치 관련된 영상은 전체적으로 빨갛게 험한 표현들이 많습니다. :)
집단 지성의 좌표 찍기
유튜브 댓글에는 영상의 시간을 적으면 바로 그 장면으로 이동할 수 있는 타임스탬프 기능이 있는데요. 개인이 재밌고 흥미롭다고 생각하는 장면의 링크를 거는 것인데 이걸 모아 놓으면 유용한 정보가 됩니다. 여러 사람이 동일한 장면을 가리키고 있으면 다른 사람들에게도 흥미 있는 지점일 테니까요. 모든 댓글에서 타임스탬프를 추출하고 시간을 구간화해 빈도를 보여주면 여러 사람이 가리키는 장면이 무엇이지가 드러납니다.
삼프로TV의 대통령 후보 정책 문답 영상에서 가장 사람들의 주목을 많이 받았던 장면은 윤석열 후보에게 경제 정책 핵심 키워드를 물었을 때 행복 경제라고 답한 장면이었네요. 경제 전문 채널의 주 시청자 집단은 구체적인 정책을 기대했는데 눈높이에 맞지 않는 답변을 했기 때문인 것 같습니다.

댓글을 다는 사람은 전체 사용자를 대표하지 않는다
댓글을 통해 시청자의 마음을 알아볼 수 있다고 가정했지만 댓글을 다는 사람들이 전체 시청자를 대표하지는 않습니다. 물론 영상의 성격에 따라 다르긴 하지만 정치, 사회적으로 이슈가 되는 영상의 경우에는 극단적인 소수 집단의 목소리가 과표집되는 경향이 높습니다. 관여도가 높은 극소수가 엄청나게 많은 댓글을 다는 경우도 있고요. 그래서 표본에서 얻은 데이터를 해석할 때는 항상 주의해야 합니다. 여론 조사나 커뮤니티의 의견을 수집하는 경우도 마찬가지입니다. 모두를 대표하는 목소리인지 목소리가 큰 일부 이익 집단의 목소리인지 잘 분별해 낼 수 있어야 합니다.
사용자의 피드백을 통해 제품(컨텐트)을 개선해 나가기
이번 글에선 하나의 영상에 달린 댓글을 여러 방식으로 탐색해보는 실험을 소개했는데요. 개별 영상의 댓글을 통한 피드백보다는 유투버가 운영하는 채널 전체 영상에서의 댓글 반응이 어떤 식으로 변화하는지 시계열로 바라보거나 k-pop이나 테크 리뷰 같은 특정 주제의 영상들의 댓글 반응 중 내 영상은 어느 정도 위치에 있는지 더 큰 데이터 집단의 공간에서 바라보면 채널을 운영하는데 보다 도움이 되는 정보를 제공할 수 있을 것 같습니다. 유튜브 채널을 운영하면서 이런 댓글을 통한 사용자 피드백을 분석해 보고 싶으시거나 이런 방식을 활용해 다수 사용자의 마음을 이해하는데 관심이 있으시면 이곳으로 의견 남겨주세요.
참고
- 워드 클라우드 - https://en.wikipedia.org/wiki/Tag_cloud
- 텍스트 네트워크 분석 - https://sicss.io/2018/materials/day3-text-analysis/text-networks/rmarkdown/SICSS_Text_Networks.html
- 보로노이 트리맵 - https://en.wikipedia.org/wiki/Voronoi_diagram
- 워드 임베딩 - https://wikidocs.net/33520
- 텍스트랭크 - https://lovit.github.io/nlp/2019/04/30/textrank/
- 카카오브레인 뽀로로 라이브러리 - https://github.com/kakaobrain/pororo
- 혐오 발언 분류 모델 SoongsilBERT:BEEP! - https://github.com/jason9693/APEACH