
2024. 8. 20. 09:29ㆍpxd AI툴 이야기
디자인 회사 홈페이지를 보면 벽에 포스트잇을 빼곡히 붙여 놓은 사진을 많이 볼 수 있는데요. 디자인 과정의 상징처럼 포스트잇을 이용한 여러 정리 방법이 있지만 어피니티 다이어그램을 사용하는 경우가 많습니다.

Affinity Diagram(어피니티 다이어그램)은 관련 아이디어나 관찰을 묶어 구조화 하는 자료 정리의 기본 과정입니다. 사용자 조사를 통해 다양한 사용자 목소리를 얻었거나 문제 해결 단계에서 다양한 아이디어가 나왔을 때 우선 비슷한 것끼리 묶어가며 핵심 아이디어를 도출합니다. 이 방법의 핵심은 다양한 관점으로 아이디어를 묶어보는 것이기 때문에 여러 사람이 함께 볼 수 있도록 큰 보드에 붙였다 떼었다 하기 편한 포스트잇을 사용하는데요. 요즘은 미로나 피그마 같은 온라인 협업 툴을 이용해 작업 하기도 합니다.

이 과정이 중요한 만큼 시간도 많이 걸립니다. 먼저 비슷한 것 끼리 모으게 되는데요. 동식물을 분류하듯 정확한 분류 체계가 있는 게 아니라서 관점에 따라 이렇게 묶을 수도 저렇게 묶을 수도 있습니다. 아이디어가 많을 수록 공통된 내용이 겹치는 경우가 많으니 이런 것만 묶어서 갯수를 줄여주면 정리가 훨씬 수월해 집니다. 지금까지 이런 인지 작업은 완전히 사람의 영역이었는데요. 자연어처리와 LLM을 사용하면서 사람이 하는 일을 완전히 대체하지는 않더라고 상당히 도와줄 수 있게 되었습니다.
클러스터링
text embedding을 이용하면 비슷한 의미의 문장을 찾아 묶을 수 있습니다. 임베딩 벡터 유사도를 이용해 가까운 것들을 묶으면 엄밀하게 같은 의미는 아니지만 단어가 사용되는 공통된 맥락을 공유하는 텍스트들을 모을 수 있습니다. 클러스터링에도 여러 방법이 있습니다. 많이 사용하는 k-means 군집화 방법은 빠르지만 랜덤 seed에 따라 시작점을 정해 매번 결과가 달라지기도 합니다. 장단점이 있지만 저는 가장 비슷한 것부터 단계적으로 묶어나가는 계층적 클러스터링 방법을 사용했습니다. 생물에서 그리는 계통수를 거꾸로 개별 요소들이 가까운 것끼리 하나씩 군집에 추가하는 방식입니다.
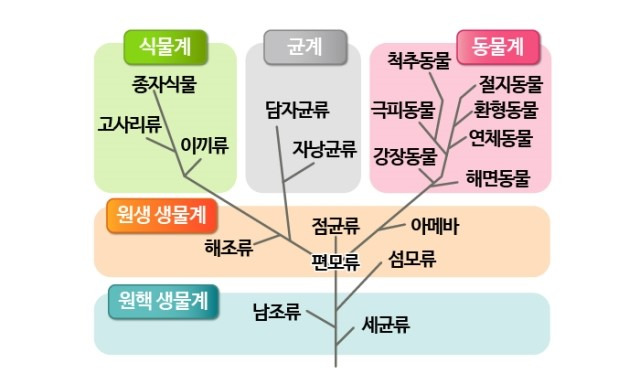
이런 군집 관계를 나타낸 그림을 덴드로그램이라고 하는데 이것도 나무를 어원으로 가지는 계통수라는 뜻입니다. 이런 관계도를 만들어 두고 어느 정도의 유사도 거리에 따라 가지를 잘라낼지 정하면 원하는 갯수의 덩어리로 묶을 수 있습니다. 이렇게 하면 원소의 갯수가 변하더라도 적절한 높이(유사도 거리)를 정해 비슷한 수준으로 묶을 수 있습니다.

어피니티 버블
예전에 새로운 사무실을 얻기 위해 사내 구성원을 대상으로 설문을 했는데요. 예시는 현재 사무실의 좋은 점에 대한 질문 답변을 모은 것입니다. 기존 사무실의 좋은 점을 유지하고 개선할 점을 보완한 사무실을 찾으려고 사용자인 구성원을 대상으로 사용자 조사를 한 것이지요. 이렇게 다양한 의견을 수집하면 우선 어떤 생각들이 있는지 어피니티 다이어그램을 이용해 정리하게 됩니다. 구글 설문을 이용해서 구글 시트에 답변을 모아 볼 수 있는데요. 이걸 텍스트 임베딩하고 클러스터링 합니다. 워드버블이라고 부르는 보로노이 다이어그램으로 그렸습니다. 비율에 따라 덩어리를 그려줘서 어떤 의견이 주요한지 한눈에 파악할 수 있습니다. 슬라이더를 이용해 클러스터 크기를 바꿔가며 적절한 수준으로 묶였는지 확인했습니다. 리서치 회사에서도 주관식 설문을 정리할때 사람이 한번 정리하면서 어떻게 분류하는 코딩 과정을 거친다고 하는데요. 이 단계를 쉽게 할 수 있습니다.

레이블링
어피니티 다이어그램에서는 레이블링이라고 하는데, 보통 다른 색의 포스트잇으로 모아놓은 내용을 대표할 수 있는 설명 문장을 적어 붙여 줍니다. 몇년 전만해도 군집의 레이블을 뽑는 걸 자동화 해보려고 TF-IDF로 중요도가 높은 키워드를 뽑고 이걸로는 부족해서 각 요소의 단어 빈도를 그래프로 나타내 중심성이 높은 문장에 가중치를 주어 군집을 대표하는 키워드를 뽑았는데요. 이제 LLM을 사용해서 “군집의 문장을 대표하는 레이블을 적어줘" 같은 간단한 프롬프트만으로도 적당한 레이블을 뽑아낼 수 있게 되었습니다. 이걸 클러스터 갯수 만큼 반복하면 되는데. 클러스터 아이디를 구분해서 전체 문장을 주고 json 형태로 클러스터 아이디와 레이블 형태로 답을 하라고 하면 한번에 결과를 얻을 수 있습니다. 데모에서는 저렴하게 chatgpt-4o-mini 모델을 사용하는데도 그럴듯한 결과가 나옵니다.
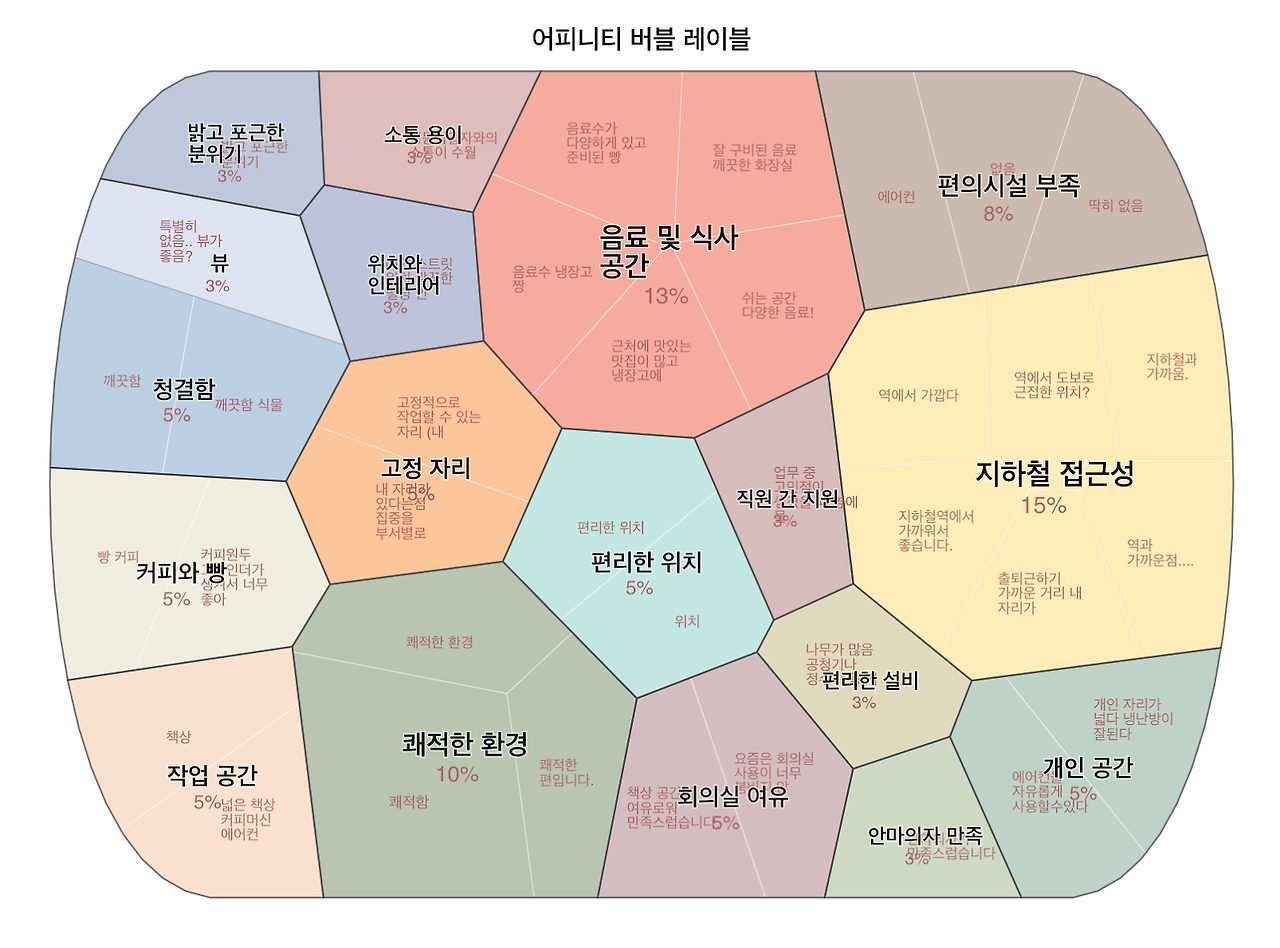
레이블 군집화
꽤 그럴듯하게 레이블링을 해주는 것 같은데. 이렇게 보니 또 비슷한 덩어리를 묶어주면 보기 편할 것 같더라구요. 계층적 클러스터링이었으니 원래의 임베딩으로 더 넓게 묶어주면 될 거라고 생각했는데요. 잘 묶이지 않았습니다. 전혀 다른 군집도 묶였는데, 자세히 살펴보면 다른 주제인데 공통된 단어를 포함한 경우에 그렇게 묶이더라구요. 그래서 추출한 레이블로 다시 임베딩을 하고 묶어주면 그럴듯 해보입니다.

정리된 클러스터링은 tsv형태로도 제공하니 시트에 복붙하면 바로 정리하는데 사용할 수 있습니다.


데모
어피니티 버블의 데모를 사용해 볼 수 있습니다. 정리가 필요한 텍스트를 붙여넣고 어피니티 버블을 만들어 보세요.
https://word-bubble-uxtechlab.replit.app/affinity
개선점
사람이 정리하는 것 만큼 완벽하지는 않고 이상한 부분도 눈에 띄지만 사람이 맨 바닥부터 시작하는 것에 비해 많은 시간을 절약할 수 있게 되었습니다. 사용한 트랜스포머 모델의 cos 유사도 평가의 피어슨 상관관계가 0.89정도인데 사람이 분류하는 것에 상당히 일치한다고 할 수 있습니다. 하지만 sentence embedding이라 짧은 단어 인 경우에 정확성이 떨어지는 문제가 있는 것 같습니다. 하지만 언어 모델은 점점 성능이 좋아지고 있으니 기대해도 좋겠습니다.