
2025. 6. 26. 07:10ㆍpxd AI툴 이야기

유튜브 댓글에서 OTT 사용자 목소리 분석하기
우리나라에서 10명 중 9명이 OTT를 본다는 사실, 알고 계셨나요? 2024년 한국콘텐츠진흥원 조사 결과에 따르면 10대에서 70대 이상까지의 OTT 이용률은 89.3%에 달합니다.
일상 깊숙이 들어온 OTT 플랫폼 시장은 최근 쿠팡플레이 무료화, 배달의민족과 티빙의 제휴, 네이버페이와 넷플릭스의 제휴 등 변화가 끊이지 않고 있습니다. 이렇게 이슈가 될 때마다 SNS, 유튜브 등에서는 사용자 의견이 쏟아져 나옵니다. 이런 자발적인 의견들은 서비스에서 직접 시행하는 조사보다 더 솔직하고 생생할 수 있죠.
하지만 그만큼 방대하고, 중요도를 판단하기도 어려운데요. 어떻게 하면 이런 의견들을 쉽고 빠르게 훑어볼 수 있을까요?
이번 포스트에서는 "OTT 플랫폼에 대한 사용자 의견"에 대해 알아보려고 합니다. 이를 위해 OTT를 비교/추천하는 유튜브 영상의 댓글란을 분석해 보았습니다. OTT 플랫폼 각각의 후기, 비교, 감상, 불만 등 다양한 의견이 자연스럽게 담겨 있었거든요. 저희가 해당 플랫폼의 리서처였다면, 분명 확인해 보고 싶은 데이터였어요. 지금부터 pxd가 진행해 본 실험 내용을 공유하고자 합니다.
(1) 데이터 준비하기
유튜브 영상 댓글을 분석하기 위해선 먼저 댓글을 불러와야겠죠? 크롤링할 수 있는 방법은 여러 가지가 있겠으나, 이번 포스트에서는 pxd가 개발 중인 '어피니티 버블'을 분석에 사용해 보려고 합니다.
어피니티 버블을 사용하면 수백 개의 정성 데이터를 빠르게 분석할 수 있는데요. 어피니티 버블 내의 유튜브 댓글 불러오기 메뉴에서 코딩이나 프로그램 설치 없이도 쉽게 댓글을 크롤링해 올 수 있습니다.


유튜브 영상의 URL을 입력하고 댓글 불러오기 버튼을 누르면, 댓글 목록이 나타납니다.
이렇게 불러온 댓글을 바로 분석하면 좋겠지만, 유튜브 댓글처럼 자유롭게 의견을 공유하는 곳에서는 단순 'ㅋㅋ'와 같은 불필요한 내용이 섞이기 마련인데요. 이런 경우, 분석 결과에도 노이즈가 섞이게 되고, 우리가 원하는 깔끔한 결과를 얻을 수 없게 됩니다.
또한, 저희는 OTT 플랫폼에 대한 사용자 의견을 모으고 싶었기 때문에 '재밌어요'나 '유익해요'와 같은 영상 자체에 대한 의견은 원하지 않았습니다. 그렇기 때문에 분석하고자 하는 주제에 해당되는 댓글만 모을 필요가 있겠습니다.
여기서 저희가 사용한 기능은 어피니티 버블의 전처리 기능입니다. 어떤 프로세스로 활용할 수 있는지 확인해 볼게요.
(2) 관련 댓글만 추출하기
데이터 전처리 전
그전에, 데이터 전처리가 얼마나 중요할까요? 먼저, 아래는 전처리 없이 분석한 버블입니다.

기본적으로 OTT 이용 행태가 구분되기는 하지만 ➊ "이용자 반응 및 태도"나 ➋ "사용자 경험 및 기능 요구" 클러스터에 묶여 있는 것을 살펴보면, OTT에 대한 사용자 의견이 아닌, 해당 영상과 채널에 대한 댓글들임을 알 수 있습니다. 또한 다양한 OTT 플랫폼이 두리뭉실하게 ➌ 하나의 클러스터(특정 OTT 플랫폼 및 기능)에 묶여 있는 모습들이 보입니다.
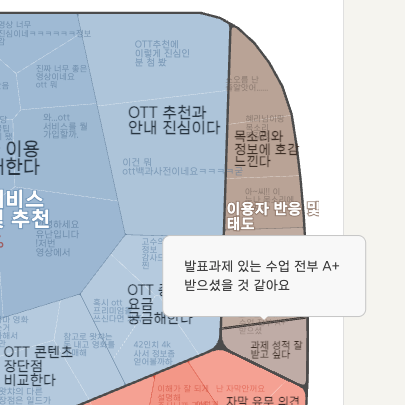

이렇게 주제와 무관한 댓글이 섞이면, AI가 제대로 클러스터를 만들기 어렵습니다. 그래서 우선 영상에 대한 댓글을 제외하고, 'OTT 이야기'만 남겨보기로 했습니다.
데이터 전처리 하기
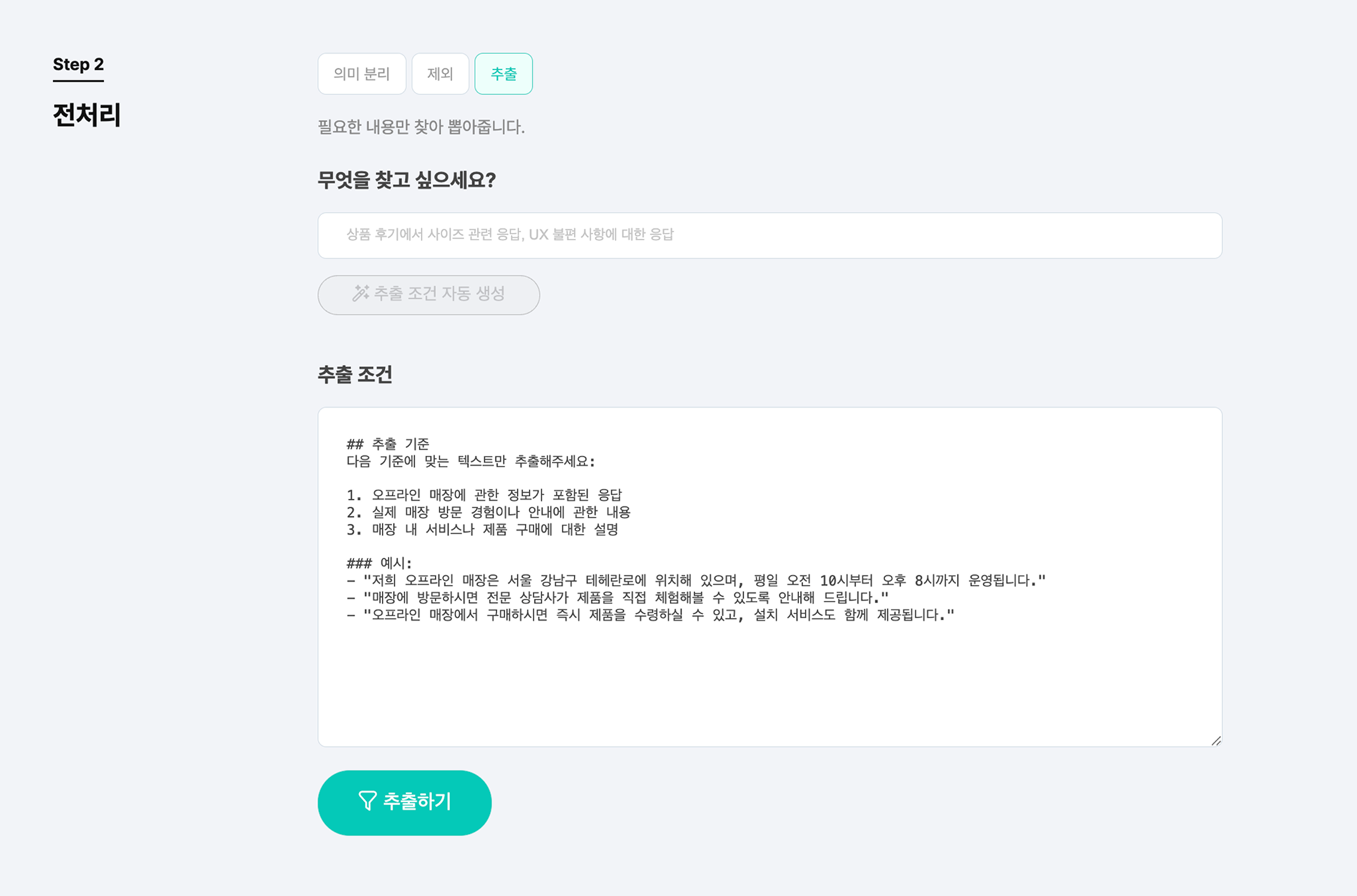
위 사진은 어피니티 버블의 데이터 전처리 시 기본으로 설정되어 있는 추출 조건입니다. 이 화면에서 저희가 원하는 추출 조건을 입력해 보겠습니다. 저희는 OTT와 관련된 댓글만 원하는데요.

데이터 맥락을 더 잘 이해하게 하기 위해 "유튜브에 달린 댓글 중 OTT에 관련된 댓글"이라고 프롬프트를 입력했습니다. 그 후 추출 조건 완성 버튼을 누르면 조건이 자동으로 생성됩니다.

여기서 시맨틱 검색 버튼을 누르면 다음과 같이 데이터가 추출되는데요. 수작업으로 직접 분리한 것과 비교했을 때, 한두 개 정도를 제외하고는 데이터가 적절하게 추출된 걸 확인할 수 있었습니다!
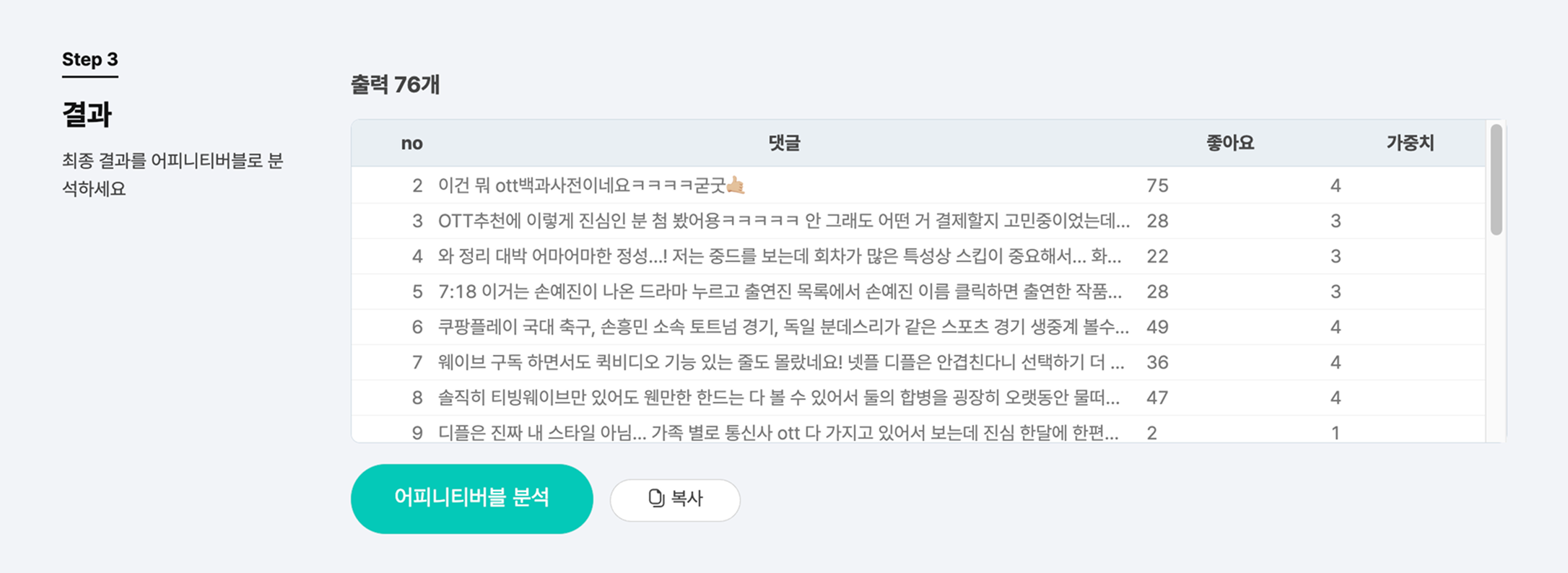
데이터 전처리 후

OTT와 연관된 댓글만 남기니 아까보다 깔끔하게 분류가 된 것을 볼 수 있습니다.
예를 들어, 이전 버블에서는 "콘텐츠 유형 및 활용 팁"과 "OTT 서비스 비교 및 추천" 클러스터의 내용이 사실상 뚜렷하게 구분되지 않았는데요. 현재는 ➊ OTT별 콘텐츠 특징, ➋ 콘텐츠 감상 후기, ➌ 기능, ➍ 구독 경험, ➎ OTT 조합 등으로 각 클러스터의 성격이 명확하게 구분되고 있습니다.
(3) 댓글의 의미를 분리하기
큼직큼직하게 사용자 의견을 볼 수 있다는 건 아주 좋습니다. 위 결과를 보고 나니, OTT별 사용자 의견을 나누어 살펴보고 싶어졌습니다. 그런데 하나의 댓글 안에 서로 다른 이야기가 섞여 있는 경우가 많은데요.

예를 들어, 위 댓글 같은 경우 총 세 가지로 의미를 분리할 수 있습니다.
- 웨이브는 예능을 좋아하면 많이 보게 된다
- 중드를 좋아한다면 웨이브나 티빙의 자막이 깔끔하다
- 디플은 마블이나 디즈니를 좋아하는 사람에게 추천한다
이런 경우 우리가 어피니티 다이어그램 작업을 할 때처럼 의미 단위로 나누어 주는 게 필요합니다. 현재 어피니티 버블에서는 해당 기능을 개발 중이며, 이번에는 수작업으로 진행해 보았습니다.


OTT 플랫폼을 중심으로 사용자 의견을 나눈 데이터를 분석한 모습입니다. 의미 단위를 분리하니 이전보다 1차 클러스터에서의 OTT 플랫폼 이름이 더 많아지고, 분명해진 것이 보이시나요?
이처럼 SNS와 유튜브 댓글의 경우 사용자들이 더욱 편하고 솔직한 이야기를 나누는 만큼, 불필요한 텍스트도 섞여 들어가게 됩니다. 유의미한 댓글을 찾고, 주제에 맞게 정리하기 위해서는 전처리 과정을 거치는 것이 좋겠습니다. 저희가 사용한 전처리 단계별 데이터는 글 하단에서 사용해 보실 수 있습니다.
마치며
지금까지 유튜브 댓글을 분석하기 위한 전처리 과정을 살펴보았습니다. 다음 글에서는 이렇게 잘 추출된 데이터를 어떻게 분석하면 좋을지, 관점과 질문을 정교화해 나가는 과정에 대해 다뤄 보려고 합니다.
OTT에 대한 유튜브 댓글 외에도, 브랜드 후기, 쇼핑몰 리뷰, VOC 등 다양한 데이터를 넣어 보세요. 실제로 어피니티 버블을 사용해 보고 싶다면 아래 링크로 접속하실 수 있습니다. 또는 이번 포스트에서 사용하였던 로우 데이터를 아래 구글 시트에서 이용하실 수 있습니다.
다른 데이터를 분석해 보고 싶다면 → 어피니티 버블 사용하기
이번 포스트의 데이터를 사용해 보고 싶다면 → 로우 데이터 사용하기
현재는 어피니티 버블 베타 버전을 제공하고 있습니다. 의견이 있다면 언제든지 댓글 또는 메일 남겨 주시길 바랍니다.