
2024. 9. 9. 16:00ㆍpxd talks
들어가며
날씨가 무더웠던 지난 7월 12일, pxd talks 에서는 ‘언어학자가 바라보는 Gen AI’ 라는 주제로 서비스나우의 언어학자이신 김미담 연사님을 모시고 강연을 진행하였습니다.
전 세계적으로 인공지능이 대중화되며 어느새 내 일상에도 깊숙이 스며들어, 생성형 AI에 대한 궁금증이 커지고 있죠. 이러한 생성형 인공지능 기술이 어떻게 만들어지는지 궁금하지 않으신가요?
첫째 : 연사님의 여정, 경계를 넘어 연결하기
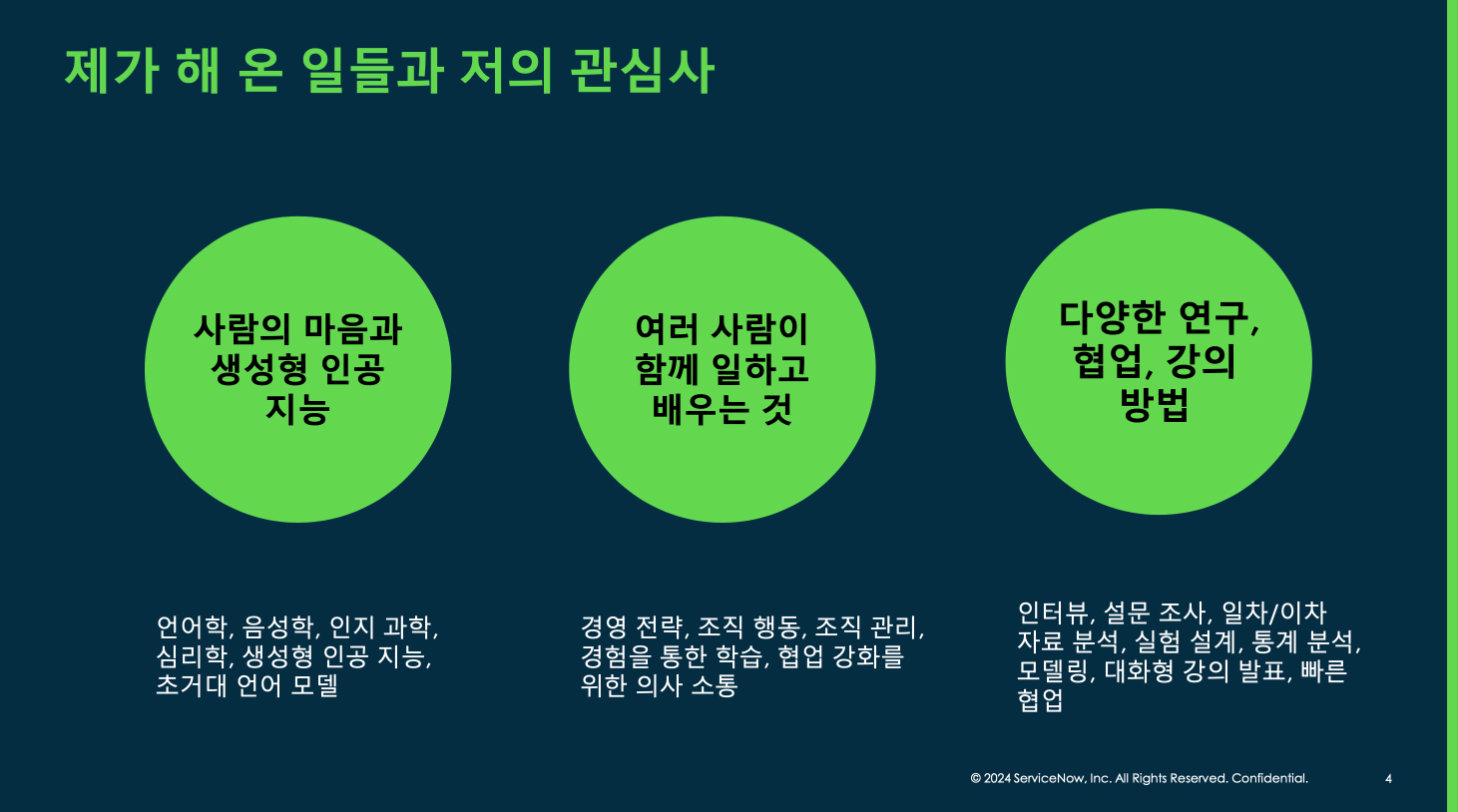
김미담 연사님은 언어학, 음성학, 인지 과학, 심리학을 전공하시고 사람의 마음을 움직이는 일에 관심이 많으셨다고 하셨어요.
꾸준한 관심으로 오랜 기간 사람들 간의 협업과 의사소통, 특히 음성 인지 및 처리 과정에 대한 연구를 진행해 오셨습니다. 더불어 효과적인 의사소통이 개인과 조직에 미치는 영향을 깊이 탐구하며, 현재는 서비스나우에서 고객 만족도 향상과 더 나은 제품 개발에 기여하고 계십니다.
둘째 : 생성형 인공지능의 시대

판별형 AI와 생성형 AI: 고양이와 강아지를 구분하는 것에서 새로운 동물을 만들어내는 것까지
지금은 정말 생성형 인공지능의 시대라고 해도 과언이 아닐 정도로 수많은 프로그램들이 쏟아져 나오고 있는데요. 특히, 생성형 인공지능이라는 기술이 주목받고 있죠. 생성형 인공지능 이전에 판별형 인공지능이라는 것이 있었어요.
판별형 인공지능과 생성형 인공지능의 차별점은 무엇일까요? 쉽게 말해서,
- 판별형 인공지능은 이미 존재하는 것들을 구분하는 역할을 해요.
예를 들어, 고양이 사진과 강아지 사진을 보고 어떤 것이 고양이고 어떤 것이 강아지인지 맞추는 거죠. - 생성형 인공지능은 이 전에 없는 새로운 무언가를 만들어내는 역할을 해요. 기존에 없던 새로운 고양이 그림을 그리거나, 고양이와 강아지를 합쳐서 전혀 새로운 동물을 만들어내는 것처럼 말이죠.
셋째 : 단어 임베딩과 생성형 AI의 시작

생성형 AI의 시작, 단어 임베딩
단어 임베딩이란 단어를 숫자로 바꾸는 작업입니다. 마치 사전에서 비슷한 뜻의 단어들이 모여 있듯이, 숫자로 바뀐 단어들도 의미가 비슷한 것끼리 가까이 붙어있게 되죠. 이렇게 단어를 숫자로 표현하고, 의미가 비슷한 단어끼리 묶는 작업을 통해 컴퓨터는 언어를 이해하고 학습할 수 있게 된 것이죠.
Age와 Gender, 굉장히 큰 말뭉치를 가지고 그 안에 있는 세부적인 단어들을 다차원의 숫자로 표현 후 추려보면 의미적으로 가까운 단어들이 서로의 집단 가까이에 묶여 분집이 생성된 걸 볼 수 있죠.
다양한 형태의 데이터 (텍스트, 이미지, 소리 등)를 넣으면 그 안에 있는 구성 요소들이 서로의 관계에 따라 자동으로 분류되고 연결됩니다. 이러한 과정을 통해 데이터의 의미를 파악하고, 더 많은 데이터를 입력할수록 더 정확한 분석 결과를 얻을 수 있다고 합니다.
단어 임베딩은 컴퓨터에게 언어를 가르치는 첫걸음이라고 할 수 있습니다. 마치 인간이 세상의 모든 단어를 하나하나 배우고, 이 단어들이 어떤 의미를 가지는지 연결하면서 언어를 익히는 것과 비슷하다고 말씀하셨어요.
넷째 : 생성형 언어 모델의 시작, 트랜스포머와 Foundation Model

트랜스포머와 셀프 어텐션: 문장의 의미를 이해하는 핵심 기술
트랜스포머라는 혁신적인 모델의 핵심은 셀프 어텐션이라는 기술입니다. 셀프 어텐션은 문장 속 단어들 간의 관계를 파악하여 중요한 정보를 추출하는 역할을 합니다.
컴퓨터는 어떻게 단어의 의미를 이해할까요?
컴퓨터는 처음부터 모든 단어의 의미를 알지 못합니다. 셀프 어텐션은 마치 컴퓨터에게 단어의 의미를 가르치는 선생님과 같습니다.
- 단어와 숫자의 연결 : 컴퓨터는 각 단어를 숫자로 변환하여 비교하고, 이를 통해 단어 간의 관계를 파악합니다.
- 단어 짝짓기 : 숫자로 변환된 단어들을 서로 비교하여 가장 관련성이 높은 단어들을 짝지어 줍니다. 이때, 관련성이 높을수록 더 높은 점수를 부여합니다.
- 의미 추론 : 예를 들어, "It is a wide street"라는 문장에서 "It"이 무엇을 가리키는지 컴퓨터는 "wide"라는 단어와의 관계를 통해 "street"임을 추론합니다.
트랜스포머와 파운데이션 모델 : 세상의 모든 지식을 가지고 있는 5살짜리 아이 같아요!
트랜스포머라는 건 문장 속 단어들이 서로 어떤 관계인지 파악해서 문장의 의미를 이해하는 아주 똑똑한 기술입니다. 마치 퍼즐 조각을 맞추듯이, 단어들을 연결해서 문장 전체의 그림을 완성하는 거죠.
파운데이션 모델은 이런 트랜스포머를 기반으로 만들어진 아주 큰 규모의 언어 모델이에요. 세상에 있는 정말 많은 책, 문서, 웹페이지 등을 학습해서 만들어졌기 때문에, 마치 세상의 모든 지식을 다 알고 있는 것처럼 보이죠.
하지만 이 모델은 아직 완벽하지 않아요. 세상의 모든 지식을 가지고 있는 5살짜리 아이는 세상에 존재하지 않죠. 아직은 실수를 하거나 예상치 못한 행동을 할 수도 있습니다. 파운데이션 모델의 예로는 Chat GPT, BERT, Llama, Mixtral 등등이 있습니다.
다섯째. 생성형 언어 모델 만들기

생성형 언어 모델을 만드는 과정을 알아보겠습니다. 실제로 회사에서 고객에게 모델을 맞게 출시하려면 많은 일들을 해야 해요.
생성형 AI 모델은 우리가 원하는 텍스트를 만들어내는 똑똑한 도구입니다. 이런 모델을 만들기 위해서는 많은 과정을 거쳐야 하는데, 마치 아이를 가르치는 것처럼 모델을 훈련시키고 발전시켜야 해요.
1단계 : 고객의 문제와 용처 파악하기
먼저, 어떤 모델이 필요한지 고객과 충분히 이야기해야 해요. 고객이 원하는 것은 무엇이고, 어떤 문제를 해결하고 싶은지 정확하게 파악하는 것이 중요해요.
2단계 : 데이터 준비하기
고객에게서 데이터를 받아 깨끗하게 정리하는 작업이 필요해요. 개인정보나 민감한 정보는 다른 정보로 바꿔서 프라이버시를 보호해야 하고, 모델 학습에 방해가 되는 불필요한 정보는 제거해야 해요.
3단계 : 모델 훈련하기
정리된 데이터를 가지고 모델을 훈련시켜요. 마치 아이에게 반복해서 가르치듯이, 모델에게도 같은 질문을 여러 번 반복해서 물어보고, 그에 대한 답변을 평가해줘요. 이 과정을 통해 모델은 점점 더 정확하고 유용한 답변을 생성할 수 있게 되죠. 이를 “휴먼 인 더 루프(HITL)”라고 합니다.
4단계 : 모델 출시
훈련된 모델을 실제 서비스에 적용해요. 고객이 원하는 결과를 잘 만들어내는지 확인하고, 필요하다면 추가적인 조정을 거쳐 최종 모델을 출시하게 됩니다.
마무리하며,
AI가 인간을 대신할 수 있는 세상이 올까요? 현재로서는 인간을 완전 대체하기엔 어려워 보이지만 AI가 인간과 협력하여 더 나은 미래를 만들어갈 것이라는 전망이 더욱 현실적이라는 생각이 듭니다.
pxd에서는 UX전문회사로서 분야를 더 발전시키고 여러가지 새로운 방향을 제시할 수 있듯이 현재 우리가 할 수 있는 일은 AI시대에 필요한 새로운 역량을 키우고, AI와 함께 동고동락하며 살아갈 준비를 해야겠죠!
흥미로운 강연을 준비해주신 김미담 연사님과 pxd talks를 준비해 주신 모든 분들, 긴 글을 읽어주신 독자분들께 다시 한번 감사드립니다.